1. Melusine¶



Free software: Apache Software License 2.0
Documentation: https://melusine.readthedocs.io.
1.1. Overview¶
Melusine is a high-level Python library for emails classification and feature extraction, written in Python and capable of running on top of Scikit-Learn, Keras or Tensorflow. It was developed with a focus on emails written in french.
- Use Melusine if you need a library which :
Supports both convolutional networks and recurrent networks, as well as combinations of the two.
Runs seamlessly on CPU and GPU.
Melusine is compatible with Python 3.6 (<=2.3.2), Python 3.7 and Python 3.8.
1.2. Release Notes¶
1.2.1. Release 2.3.5¶
- Bug fix:
PR139: Fix config search with a recursive paramater.
1.2.2. Release 2.3.4¶
- New features:
PR 128: A Lemmatizer class has been added by the Société Générale team! Lemmatizer object is compatible with sklearn pipelines and is built around an sklearn Transformer. Details can be found in [tutorial 04](https://github.com/MAIF/melusine/blob/master/tutorial/tutorial04_nlp_tools.ipynb) and [08](https://github.com/MAIF/melusine/blob/master/tutorial/tutorial08_full_pipeline_detailed.ipynb)
PR 132: A `Stemmer`class has been added. Details can also be found in tutorial 04.
PR 132: A `DeterministicEmojiFlagger`class has been added to flag emojis. Details can be found in tutorial 08.
- Updates:
Python 3.6 is no longer supported for tensorflow compatibility issues. Melusine is now running with Tensorflow 2.8
PR 121: Add the return of the histogram after the training (train.py)
PR 120: Tokenizer can now be specified in a NeuralModel init. Embedding and Phraser classes have been simplified. See [tutorial 04](https://github.com/MAIF/melusine/blob/master/tutorial/tutorial04_nlp_tools.ipynb)
PR 120: Config has been split into different functionalities files that can be found in /melusine/config/parameters for more readability. See [tutorial 10](https://github.com/MAIF/melusine/blob/master/tutorial/tutorial10_conf_file.ipynb)
PR 120: A text_flagger`and a `token_flagger class have been created to give you a glimpse of the library redesign but are not called yet.
- Bug fix:
PR 124: fixing purge of dict_attr keys while saving bert models (train.py)
Issue 126: fixing initialisation of bert_tokenizer for cross validation (train.py)
1.2.3. Release 2.3.2¶
- Updates:
Compatibility with python 3.7 and 3.8
Optional dependencies (viz, transformers, all)
Specify custom configurations with environment variable MELUSINE_CONFIG_DIR
Use any number of JSON and YAML files for configurations
(instead of just one config file)
- Bug fix:
Fixed bug when training transformers model without meta features
1.2.4. Release 2.3¶
- New features:
Added a class ExchangeConnector to interact with an Exchange Mailbox
Added new tutorial tutorial14_exchange_connector to demonstrate the usage of the ExchangeConnector class
- Updates:
Gensim upgrade ([4.0.0](https://github.com/RaRe-Technologies/gensim/releases))
Propagate modifications stemming from the Gensim upgrade (code and tutorials)
Package deployment : switch from Travis CI to Github actions
1.2.5. Release 2.0¶
- New features:
Attentive Neural Networks are now available. :tada: We propose you an original Transformer architecture as well as pre-trained BERT models (Camembert and Flaubert)
Tutorial 13 will explain you how to get started with these models and attempt to compare them.
Validation data can now be used to train models (See fit function from NeuralModel for usage)
The activation function can now be modified to adapt to your needs (See NeuralModel init for usage)
1.2.6. Release 1.10.0¶
- Updates:
Melusine is now running with Tensorflow 2.2
1.2.7. Release 1.9.6¶
- New features:
Flashtext library is now used to flag names instead of regex. It allows a faster computation.
1.2.8. Release 1.9.5¶
- New features:
An Ethics Guide is now available to evaluate AI projects, with guidelines and questionnaire. The questionnaire is based on criteria derived in particular from the work of the European Commission and grouped by categories.
Melusine also offers an easy and nice dashboard app with StreamLit. The App contains exploratory dashboard on the email dataset and a more specific study on discrimination between the dataset and a neural model classification.
1.3. The Melusine package¶
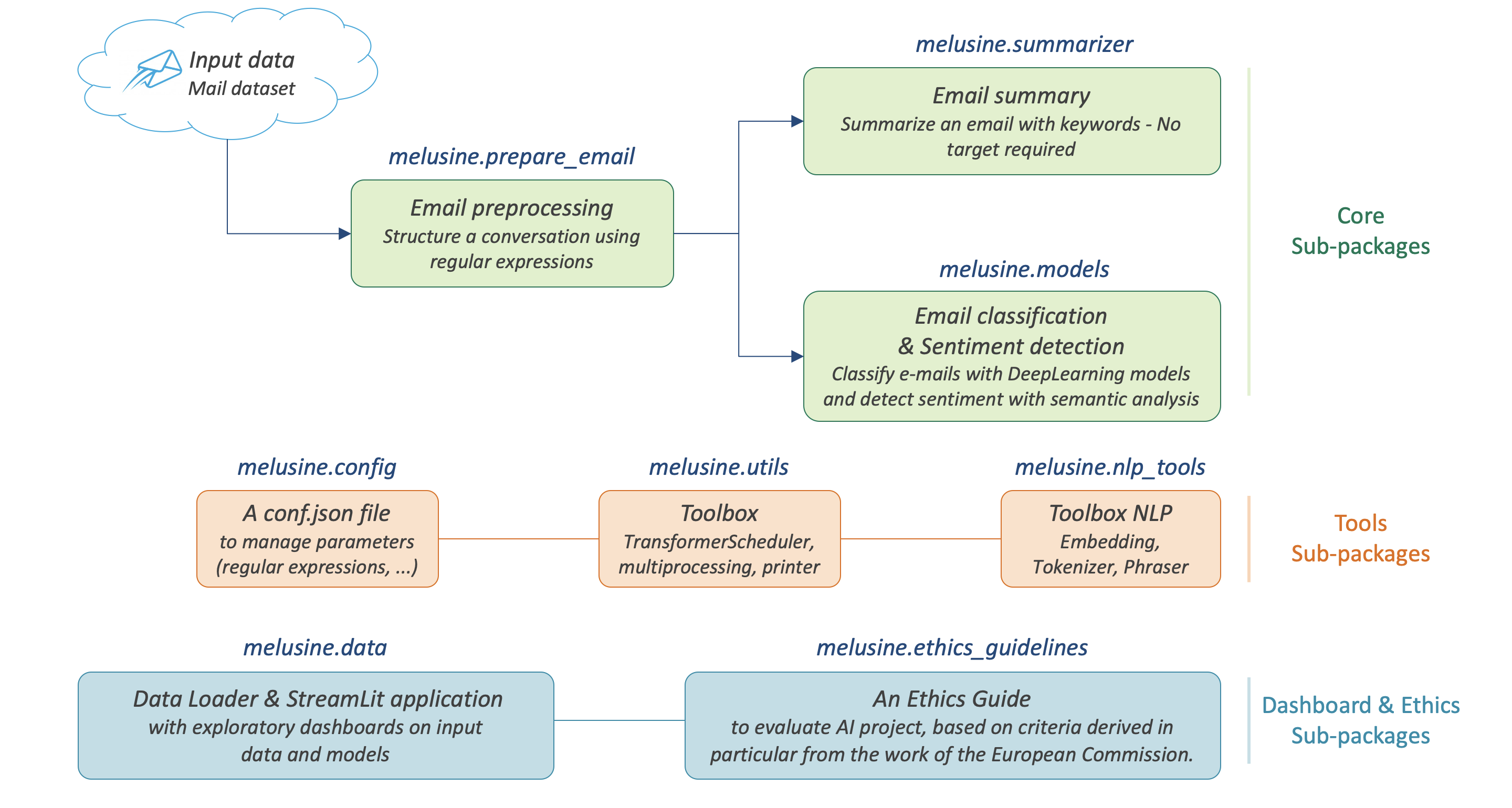
This package is designed for the preprocessing, classification and automatic summarization of emails written in french. 3 main subpackages are offered :
prepare_email : to preprocess and clean the emails.
summarizer : to extract keywords from an email.
models : to classify e-mails according to categories pre-defined defined by the user.
2 other subpackages are offered as building blocks :
nlp_tools : to provide classic NLP tools such as tokenizer, phraser and embeddings.
utils : to provide a TransformerScheduler class to build your own transformer and integrate it into a scikit-learn Pipeline.
An other subpackage is also provided to manage, modify or add parameters such as : regular expressions, keywords, stopwords, etc.
config : contains ConfigJsonReader class to setup and handle a conf.json file. This JSON file is the core of this package since it’s used by different submodules to preprocess the data.
1.4. Getting started : 30 seconds to Melusine¶
1.4.1. Importing Melusine¶
To use Melusine in a project:
import melusine
1.4.2. Input data : Email DataFrame¶
The basic requirement to use Melusine is to have an input e-mail DataFrame with the following columns:
body : Body of an email (single message or conversation history)
header : Header of an email
date : Reception date of an email
from : Email address of the sender
to (optional): Email address of the recipient
label (optional): Label of the email for a classification task (examples: Business, Spam, Finance or Family)
body |
header |
date |
from |
to |
label |
|---|---|---|---|---|---|
Thank you.\nBye,\nJohn |
Re: Your order |
jeudi 24 mai 2018 11 h 49 CEST |
?? |
To import the test dataset:
from melusine.data.data_loader import load_email_data
df_email = load_email_data()
1.4.3. Pre-processing pipeline¶
A working pre-processing pipeline is given below:
from sklearn.pipeline import Pipeline
from melusine.utils.transformer_scheduler import TransformerScheduler
from melusine.prepare_email.manage_transfer_reply import check_mail_begin_by_transfer, update_info_for_transfer_mail, add_boolean_answer, add_boolean_transfer
from melusine.prepare_email.build_historic import build_historic
from melusine.prepare_email.mail_segmenting import structure_email
from melusine.prepare_email.body_header_extraction import extract_last_body
from melusine.prepare_email.cleaning import clean_body
ManageTransferReply = TransformerScheduler(
functions_scheduler=[
(check_mail_begin_by_transfer, None, ['is_begin_by_transfer']),
(update_info_for_transfer_mail, None, None),
(add_boolean_answer, None, ['is_answer']),
(add_boolean_transfer, None, ['is_transfer'])
])
EmailSegmenting = TransformerScheduler(
functions_scheduler=[
(build_historic, None, ['structured_historic']),
(structure_email, None, ['structured_body'])
])
Cleaning = TransformerScheduler(
functions_scheduler=[
(extract_last_body, None, ['last_body']),
(clean_body, None, ['clean_body'])
])
prepare_data_pipeline = Pipeline([
('ManageTransferReply', ManageTransferReply),
('EmailSegmenting', EmailSegmenting),
('Cleaning', Cleaning),
])
df_email = prepare_data_pipeline.fit_transform(df_email)
1.4.4. Phraser and Tokenizer pipeline¶
A pipeline to train and apply the phraser end tokenizer is given below:
from melusine.nlp_tools.phraser import Phraser
from melusine.nlp_tools.tokenizer import Tokenizer
tokenizer = Tokenizer (input_column='clean_body', output_column="tokens")
df_email = tokenizer.fit_transform(df_email)
phraser = Phraser(
input_column='tokens',
output_column='phrased_tokens',
threshold=5,
min_count=2
)
_ = phraser.fit(df_email)
df_email = phraser.transform(df_email)
1.4.5. Embeddings training¶
An example of embedding training is given below:
from melusine.nlp_tools.embedding import Embedding
embedding = Embedding(
tokens_column='tokens',
size=300,
workers=4,
min_count=3
)
embedding.train(df_email)
1.4.6. Metadata pipeline¶
A pipeline to prepare the metadata is given below:
from melusine.prepare_email.metadata_engineering import MetaExtension, MetaDate, Dummifier
metadata_pipeline = Pipeline([
('MetaExtension', MetaExtension()),
('MetaDate', MetaDate()),
('Dummifier', Dummifier())
])
df_meta = metadata_pipeline.fit_transform(df_email)
1.4.7. Keywords extraction¶
An example of keywords extraction is given below:
from melusine.summarizer.keywords_generator import KeywordsGenerator
keywords_generator = KeywordsGenerator()
df_email = keywords_generator.fit_transform(df_email)
1.4.8. Classification¶
The package includes multiple neural network architectures including CNN, RNN, Attentive and pre-trained BERT Networks. An example of classification is given below:
from sklearn.preprocessing import LabelEncoder
from melusine.models.neural_architectures import cnn_model
from melusine.models.train import NeuralModel
X = df_email.drop(['label'], axis=1)
y = df_email.label
le = LabelEncoder()
y = le.fit_transform(y)
pretrained_embedding = embedding
nn_model = NeuralModel(architecture_function=cnn_model,
pretrained_embedding=pretrained_embedding,
text_input_column='clean_body')
nn_model.fit(X, y)
y_res = nn_model.predict(X)
1.5. Glossary¶
1.5.1. Pandas dataframes columns¶
Because Melusine manipulates pandas dataframes, the naming of the columns is imposed. Here is a basic glossary to provide an understanding of each columns manipulated. Initial columns of the dataframe:
body : the body of the email. It can be composed of a unique message, a history of messages, a transfer of messages or a combination of history and transfers.
header : the subject of the email.
date : the date the email has been sent. It corresponds to the date of the last message of the email has been written.
from : the email address of the author of the last message of the email.
to : the email address of the recipient of the last message.
Columns added by Melusine:
is_begin_by_transfer : boolean, indicates if the email is a direct transfer. In that case it is recommended to update the value of the initial columns with the informations of the message transferred.
is_answer : boolean, indicates if the email contains a history of messages
is_transfer : boolean, indicates if the email is a transfer (in that case it does not have to be a direct transfer).
structured_historic : list of dictionaries, each dictionary corresponds to a message of the email. The first dictionary corresponds to the last message (the one that has been written) while the last dictionary corresponds to the first message of the history. Each dictionary has two keys :
meta : to access the metadata of the message as a string.
text : to access the message itself as a string.
structured_body : list of dictionaries, each dictionary corresponds to a message of the email. The first dictionary corresponds to the last message (the one that has been written) while the last dictionary corresponds to the first message of the history. Each dictionary has two keys :
meta : to access the metadata of the message as a dictionary. The dictionary has three keys:
date : the date of the message.
from : the email address of the author of the message.
to : the email address of the recipient of the message.
text : to access the message itself as a dictionary. The dictionary has two keys:
header : the subject of the message.
structured_text : the different parts of the message segmented and tagged as a list of dictionaries. Each dictionary has two keys:
part : to access the part of the message as a string.
tags : to access the tag of the part of the message.
last_body : string, corresponds to the part of the last message of the email that has been tagged as “BODY”.
clean_body : string, corresponds a cleaned last_body.
clean_header : string, corresponds to a cleaned header.
clean_text : string, concatenation of clean_header and clean_body.
tokens : list of strings, corresponds to a tokenized column, by default clean_text.
keywords : list of strings, corresponds to the keywords of extracted from the tokens column.
stemmed_tokens : list of strings, corresponds to a stemmed column, by default stemmed_tokens.
lemma_spacy_sm : string, corresponds to a lemmatized column.
lemma_lefff : string, corresponds to a lemmatized column.
1.6. Motivation & history¶
1.6.1. Origin of the project¶
MAIF, being one of the leading mutual insurance companies in France, receives daily a large volume of emails from its clients and is under pressure to reply to their requests as efficiently as possible. As such an efficient routing system is of the upmost importance to assign each emails to its right entity. However the previously outdated routing system put the company under ever increasing difficulties to fulfill its pledge. In order to face up to this challenge, MAIF has implemented a new routing system based on state-of-the-art NLP and Deep Learning techniques that would classify each email under the right label according to its content and extract the relevant information to help the MAIF counsellors processing the emails.
1.6.2. Ambitions of the project¶
Melusine is the first Open Source and free-of-use solution dedicated specifically to the qualification of e-mails written in french. The ambition of this Python package is to become a reference, but also to live in the French NLP community by federating users and contributors. Initially developed to answer the problem of routing e-mails received by the MAIF, the solution was implemented using state-of-the-art techniques in Deep Learning and NLP. Melusine can be interfaced with Scikit-Learn: it offers the user the possibility to train his own classification and automatic summarization model according to the constraints of his problem.
1.6.3. Why Melusine ?¶
Following MAIF’s tradition to name its open source packages after deities, it was chosen to release this package under the name of Melusine as an homage to a legend from the local folklore in the Poitou region in France where MAIF is historically based.
1.7. Credits¶
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template.